Apr 9, 2025
Apr 9, 2025
Apr 9, 2025
HDSI Alumni Spotlight Spring 2025 Speech
On April 9, 2025, I was fortunate to give a speech, titled 'At the Front Lines of AI', to current Data Science students at UCSD. In this talk, I explored how GPU technology powers the modern AI revolution. I also discussed how these advances are reshaping data science education, and highlighted the growing importance of systems fluency, distributed training, and responsible AI integration. The talk concluded with a reflection on how students can embrace AI as a tool and a partner, without losing sight of the human qualities—like creativity, ethics, and adaptability—that remain irreplaceable.
Author
Camille Dunning
Camille Dunning
READ
20 - 25 Minutes
20 - 25 Minutes
Category
Events
Events

At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
View the slideshow here. A recording of the speech will be uploaded soon. The speech lasted a total of around 40 minutes, with 15 minutes at the end for a Q&A.
This speech was delivered as the spring 2025 alumni spotlight at the Halıcıoğlu Data Science Institute, UC San Diego:
About Me
Let me begin by introducing myself. First and foremost, I am a cat addict. I'm also a hobbyist electronic music producer and sound designer.
During my freshman year at UCSD, I got my foot in the door through networking, research scholarships, and working unpaid internship positions at San Diego startups. The summer after my sophomore year, I landed my first big company internship at BlackRock, where I helped migrate terabytes of the Aladdin Product Group's post-trade accounting data from Apache Cassandra to Snowflake.
The summer after, I did cybersecurity work at Salesforce, where I automated phishing detection tasks over the hundreds of new sites that were hosted on Heroku per day (fun fact: I caught and pre-empted an attack against the Nepali Air Force). I joined NVIDIA Robotics in the subsequent fall where I worked on synthetic data generation pipelines for their robotics training environments. The following spring, I joined Tesla, where I built the forecasting model for factory throughput for the Cybertruck, and improved failure mode detection for bolt fastening with torque data.
After graduating, I returned to NVIDIA, this time under the Deep Learning Compiler organization, supporting verification efforts for the XLA compiler and JAX on NVIDIA GPUs. I am now currently residing in San Jose with [my cats] Bijoux and Pompom.
The Critical Role of GPUs in Modern AI
Our company's namesake is 'Invidia', which refers to the Roman goddess of envy (pictured below).
Our mission is to create such advanced graphics and AI technology that it genuinely inspires both admiration and, perhaps, a bit of envy among our competitors.
GPUs have revolutionized AI by enabling massive parallel computation that drastically speeds up the training, and more recently, inference, of complex models—think image recognition, natural language processing, and autonomous driving.
What helps NVIDIA in continuing to push the boundaries of AI is the synergy between high-performance hardware and cutting-edge software solutions.
Evolution of AI Hardware from CPUs to GPUs
The 2012 AlexNet breakthrough was a landmark moment, one of the first that showcased the raw power of GPUs for deep learning. AlexNet drastically outperformed other models at the time, essentially proving that GPUs weren't just for graphics anymore.
This success helped democratize AI research and development across both academia and industry, because suddenly, smaller labs could train complex models much faster and more affordably than if they were relying on traditional CPUs.
A key milestone is the introduction in 2006 of CUDA, which made it easier for developers to program GPUs in familiar languages like C/C++, unlocking general-purpose GPU computing beyond graphics.
A big part of this story is how each new GPU generation typically brings a 2-3x improvement in AI performance. This is in large part because each GPU generation increases the number of streaming multiprocessors (SMs), which handle parallel workloads.
It also boosts memory bandwidth, which is a key factor in feeding data quickly to the SM.
It also integrates specialized cores—like Tensor Cores—which accelerate mixed-precision arithmetic (i.e., FP16, TF32, INT8) specifically tuned for deep learning.
Finally, the Transformer Engines were introduced in 2022. These are optimized specifically for LLMs with transformer-based architectures.
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Why GPUs Revolutionized AI: Architecture Advantages
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Modern GPUs have thousands of cores—far more than the few dozen on a typical CPU. This massive parallelism means GPUs can execute many operations concurrently.
It's also not just having 'more cores', but having cores designed specifically for high throughput on tightly packed computations.
Beyond raw core count, GPUs also come with advanced memory architectures—like stacked memory and specialized caches—to feed their parallel compute engines, so we have a nice synergy of parallel cores and memory bandwidth that's tailor-made for the dense, iterative operations that define neural networks.
Historically, training complex models on CPU clusters could run into the millions of dollars in hardware, power, and cooling. GPUs slash those costs by orders of magnitude, sometimes into the thousands or even hundreds of dollars, particularly when leveraging cloud services that let you pay only for what you need.
This budget-friendly approach means that smaller labs and startups can now compete with big tech companies, leveling the playing field.
When training becomes cheaper, you can do it more frequently and iterate on models faster. That shorter feedback loop drivers faster breakthroughs.
Scaling AI with Multi-GPU Computing: Model Growth & Enabling Technologies
Over the past few years, we've seen model sizes skyrocket—BERT had around 340 million parameters; GPT-3 jumped to 175 billion; and now some modern Large Language Models are rumored to be beyond the trillion-parameter mark.
These leaps in scale require not just a single powerful GPU, but clusters of GPUs working together (pictured below: NVIDIA Blackwell Ultra DGX SuperPOD).
Of course, a huge challenge here is coordinating multiple GPUs without bogging them down in communication overhead. This is where innovations like NVLink, InfiniBand, and high-bandwidth interconnects come in. When you're splitting massive models across multiple devices, these technologies let GPUs exchange data extremely quickly.
To fully harness multi-GPU systems, AI frameworks and compilers now optimize code for distributed training. They automatically handle data-parallel or model-parallel strategies—partitioning model layers or data batches across different GPUs.
NVIDIA's own software stacks, including libraries like NCCL, make it easier for developers to achieve near-linear scaling when adding more GPUs.
With trillion parameter models, even minimal inefficiencies can can balloon costs and training times. That's why advanced optimizations—like reduced-precision data types, optimized all-reduce algorithms, and smart partitioning—are absolutely vital.
These improvements can shave weeks off training times and slash infrastructure costs.
Multi-GPU setups may seem expensive up front, but if we tackle extremely large models in parallel, we'll dramatically cut the total time and energy needed to train, meaning more experiments in less time.
View the slideshow here. A recording of the speech will be uploaded soon. The speech lasted a total of around 40 minutes, with 15 minutes at the end for a Q&A.
This speech was delivered as the spring 2025 alumni spotlight at the Halıcıoğlu Data Science Institute, UC San Diego:
About Me
Let me begin by introducing myself. First and foremost, I am a cat addict. I'm also a hobbyist electronic music producer and sound designer.
During my freshman year at UCSD, I got my foot in the door through networking, research scholarships, and working unpaid internship positions at San Diego startups. The summer after my sophomore year, I landed my first big company internship at BlackRock, where I helped migrate terabytes of the Aladdin Product Group's post-trade accounting data from Apache Cassandra to Snowflake.
The summer after, I did cybersecurity work at Salesforce, where I automated phishing detection tasks over the hundreds of new sites that were hosted on Heroku per day (fun fact: I caught and pre-empted an attack against the Nepali Air Force). I joined NVIDIA Robotics in the subsequent fall where I worked on synthetic data generation pipelines for their robotics training environments. The following spring, I joined Tesla, where I built the forecasting model for factory throughput for the Cybertruck, and improved failure mode detection for bolt fastening with torque data.
After graduating, I returned to NVIDIA, this time under the Deep Learning Compiler organization, supporting verification efforts for the XLA compiler and JAX on NVIDIA GPUs. I am now currently residing in San Jose with [my cats] Bijoux and Pompom.
The Critical Role of GPUs in Modern AI
Our company's namesake is 'Invidia', which refers to the Roman goddess of envy (pictured below).
Our mission is to create such advanced graphics and AI technology that it genuinely inspires both admiration and, perhaps, a bit of envy among our competitors.
GPUs have revolutionized AI by enabling massive parallel computation that drastically speeds up the training, and more recently, inference, of complex models—think image recognition, natural language processing, and autonomous driving.
What helps NVIDIA in continuing to push the boundaries of AI is the synergy between high-performance hardware and cutting-edge software solutions.
Evolution of AI Hardware from CPUs to GPUs
The 2012 AlexNet breakthrough was a landmark moment, one of the first that showcased the raw power of GPUs for deep learning. AlexNet drastically outperformed other models at the time, essentially proving that GPUs weren't just for graphics anymore.
This success helped democratize AI research and development across both academia and industry, because suddenly, smaller labs could train complex models much faster and more affordably than if they were relying on traditional CPUs.
A key milestone is the introduction in 2006 of CUDA, which made it easier for developers to program GPUs in familiar languages like C/C++, unlocking general-purpose GPU computing beyond graphics.
A big part of this story is how each new GPU generation typically brings a 2-3x improvement in AI performance. This is in large part because each GPU generation increases the number of streaming multiprocessors (SMs), which handle parallel workloads.
It also boosts memory bandwidth, which is a key factor in feeding data quickly to the SM.
It also integrates specialized cores—like Tensor Cores—which accelerate mixed-precision arithmetic (i.e., FP16, TF32, INT8) specifically tuned for deep learning.
Finally, the Transformer Engines were introduced in 2022. These are optimized specifically for LLMs with transformer-based architectures.
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Why GPUs Revolutionized AI: Architecture Advantages
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Modern GPUs have thousands of cores—far more than the few dozen on a typical CPU. This massive parallelism means GPUs can execute many operations concurrently.
It's also not just having 'more cores', but having cores designed specifically for high throughput on tightly packed computations.
Beyond raw core count, GPUs also come with advanced memory architectures—like stacked memory and specialized caches—to feed their parallel compute engines, so we have a nice synergy of parallel cores and memory bandwidth that's tailor-made for the dense, iterative operations that define neural networks.
Historically, training complex models on CPU clusters could run into the millions of dollars in hardware, power, and cooling. GPUs slash those costs by orders of magnitude, sometimes into the thousands or even hundreds of dollars, particularly when leveraging cloud services that let you pay only for what you need.
This budget-friendly approach means that smaller labs and startups can now compete with big tech companies, leveling the playing field.
When training becomes cheaper, you can do it more frequently and iterate on models faster. That shorter feedback loop drivers faster breakthroughs.
Scaling AI with Multi-GPU Computing: Model Growth & Enabling Technologies
Over the past few years, we've seen model sizes skyrocket—BERT had around 340 million parameters; GPT-3 jumped to 175 billion; and now some modern Large Language Models are rumored to be beyond the trillion-parameter mark.
These leaps in scale require not just a single powerful GPU, but clusters of GPUs working together (pictured below: NVIDIA Blackwell Ultra DGX SuperPOD).
Of course, a huge challenge here is coordinating multiple GPUs without bogging them down in communication overhead. This is where innovations like NVLink, InfiniBand, and high-bandwidth interconnects come in. When you're splitting massive models across multiple devices, these technologies let GPUs exchange data extremely quickly.
To fully harness multi-GPU systems, AI frameworks and compilers now optimize code for distributed training. They automatically handle data-parallel or model-parallel strategies—partitioning model layers or data batches across different GPUs.
NVIDIA's own software stacks, including libraries like NCCL, make it easier for developers to achieve near-linear scaling when adding more GPUs.
With trillion parameter models, even minimal inefficiencies can can balloon costs and training times. That's why advanced optimizations—like reduced-precision data types, optimized all-reduce algorithms, and smart partitioning—are absolutely vital.
These improvements can shave weeks off training times and slash infrastructure costs.
Multi-GPU setups may seem expensive up front, but if we tackle extremely large models in parallel, we'll dramatically cut the total time and energy needed to train, meaning more experiments in less time.
View the slideshow here. A recording of the speech will be uploaded soon. The speech lasted a total of around 40 minutes, with 15 minutes at the end for a Q&A.
This speech was delivered as the spring 2025 alumni spotlight at the Halıcıoğlu Data Science Institute, UC San Diego:
About Me
Let me begin by introducing myself. First and foremost, I am a cat addict. I'm also a hobbyist electronic music producer and sound designer.
During my freshman year at UCSD, I got my foot in the door through networking, research scholarships, and working unpaid internship positions at San Diego startups. The summer after my sophomore year, I landed my first big company internship at BlackRock, where I helped migrate terabytes of the Aladdin Product Group's post-trade accounting data from Apache Cassandra to Snowflake.
The summer after, I did cybersecurity work at Salesforce, where I automated phishing detection tasks over the hundreds of new sites that were hosted on Heroku per day (fun fact: I caught and pre-empted an attack against the Nepali Air Force). I joined NVIDIA Robotics in the subsequent fall where I worked on synthetic data generation pipelines for their robotics training environments. The following spring, I joined Tesla, where I built the forecasting model for factory throughput for the Cybertruck, and improved failure mode detection for bolt fastening with torque data.
After graduating, I returned to NVIDIA, this time under the Deep Learning Compiler organization, supporting verification efforts for the XLA compiler and JAX on NVIDIA GPUs. I am now currently residing in San Jose with [my cats] Bijoux and Pompom.
The Critical Role of GPUs in Modern AI
Our company's namesake is 'Invidia', which refers to the Roman goddess of envy (pictured below).
Our mission is to create such advanced graphics and AI technology that it genuinely inspires both admiration and, perhaps, a bit of envy among our competitors.
GPUs have revolutionized AI by enabling massive parallel computation that drastically speeds up the training, and more recently, inference, of complex models—think image recognition, natural language processing, and autonomous driving.
What helps NVIDIA in continuing to push the boundaries of AI is the synergy between high-performance hardware and cutting-edge software solutions.
Evolution of AI Hardware from CPUs to GPUs
The 2012 AlexNet breakthrough was a landmark moment, one of the first that showcased the raw power of GPUs for deep learning. AlexNet drastically outperformed other models at the time, essentially proving that GPUs weren't just for graphics anymore.
This success helped democratize AI research and development across both academia and industry, because suddenly, smaller labs could train complex models much faster and more affordably than if they were relying on traditional CPUs.
A key milestone is the introduction in 2006 of CUDA, which made it easier for developers to program GPUs in familiar languages like C/C++, unlocking general-purpose GPU computing beyond graphics.
A big part of this story is how each new GPU generation typically brings a 2-3x improvement in AI performance. This is in large part because each GPU generation increases the number of streaming multiprocessors (SMs), which handle parallel workloads.
It also boosts memory bandwidth, which is a key factor in feeding data quickly to the SM.
It also integrates specialized cores—like Tensor Cores—which accelerate mixed-precision arithmetic (i.e., FP16, TF32, INT8) specifically tuned for deep learning.
Finally, the Transformer Engines were introduced in 2022. These are optimized specifically for LLMs with transformer-based architectures.
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Why GPUs Revolutionized AI: Architecture Advantages
In short, GPUs aren't just faster processors; they embody a parallel-first design that dramatically reshapes what's possible in AI.
As AI models grow more complex, we expect to see further specialized hardware improvements—from memory hierarchy tweaks to next-gen tensor processing units.
Modern GPUs have thousands of cores—far more than the few dozen on a typical CPU. This massive parallelism means GPUs can execute many operations concurrently.
It's also not just having 'more cores', but having cores designed specifically for high throughput on tightly packed computations.
Beyond raw core count, GPUs also come with advanced memory architectures—like stacked memory and specialized caches—to feed their parallel compute engines, so we have a nice synergy of parallel cores and memory bandwidth that's tailor-made for the dense, iterative operations that define neural networks.
Historically, training complex models on CPU clusters could run into the millions of dollars in hardware, power, and cooling. GPUs slash those costs by orders of magnitude, sometimes into the thousands or even hundreds of dollars, particularly when leveraging cloud services that let you pay only for what you need.
This budget-friendly approach means that smaller labs and startups can now compete with big tech companies, leveling the playing field.
When training becomes cheaper, you can do it more frequently and iterate on models faster. That shorter feedback loop drivers faster breakthroughs.
Scaling AI with Multi-GPU Computing: Model Growth & Enabling Technologies
Over the past few years, we've seen model sizes skyrocket—BERT had around 340 million parameters; GPT-3 jumped to 175 billion; and now some modern Large Language Models are rumored to be beyond the trillion-parameter mark.
These leaps in scale require not just a single powerful GPU, but clusters of GPUs working together (pictured below: NVIDIA Blackwell Ultra DGX SuperPOD).
Of course, a huge challenge here is coordinating multiple GPUs without bogging them down in communication overhead. This is where innovations like NVLink, InfiniBand, and high-bandwidth interconnects come in. When you're splitting massive models across multiple devices, these technologies let GPUs exchange data extremely quickly.
To fully harness multi-GPU systems, AI frameworks and compilers now optimize code for distributed training. They automatically handle data-parallel or model-parallel strategies—partitioning model layers or data batches across different GPUs.
NVIDIA's own software stacks, including libraries like NCCL, make it easier for developers to achieve near-linear scaling when adding more GPUs.
With trillion parameter models, even minimal inefficiencies can can balloon costs and training times. That's why advanced optimizations—like reduced-precision data types, optimized all-reduce algorithms, and smart partitioning—are absolutely vital.
These improvements can shave weeks off training times and slash infrastructure costs.
Multi-GPU setups may seem expensive up front, but if we tackle extremely large models in parallel, we'll dramatically cut the total time and energy needed to train, meaning more experiments in less time.


At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
GPU Technology and the Data Science Students
As the AI landscape evolves at a breakneck pace, there's a rapidly growing need for data scientists who understand how to leverage parallel computing, distributed training, and specialized libraries.
In other words, it's no longer just about knowing machine learning algorithms; it's also about understanding the platforms that make these algorithms run efficiently at scale.
I am going to go into how being fluent in GPU-accelerated data science gives you a competitive edge as AI continues to expand into every corner of industry and academia.
Changing Skill Requirements
Today's data scientists increasingly need to know how their frameworks tap into GPU resources.
This doesn't need to be about writing low-level GPU kernels from scratch, but it does involve understanding how tensor operations map on to GPU threads or blocks.
This might include recognizing when your data loading it bottlenecking your GPU, or how asynchronous CPU/GPU operations can overlap to reduce idle time.
It's nice to have a mental of model of the GPU's concurrency and memory hierarchy, potential to boost training efficiency.
Even though GPUs are powerful, they're not always abundant. Cloud environments often charge by the minute or hour for GPU usage, and on-premise clusters are shared resources.
We're seeing techniques like model and gradient checkpointing, mixed precision, and layer-wise parallelism. These are no longer 'nice to have features"; they can be the difference between training a model in days versus weeks, or paying thousands of dollars versus tens of thousands.
Additionally, choosing the right GPU instance type or optimizing batch sizes can have huge cost implications. The more you understand memory footprints and parallel workloads, the more effective you'll be in budgeting and scaling your experiments.
Single-GPU training is becoming increasingly unrealistic as models balloon into billions or trillions of parameters. You'll need to design systems that coordinate multiple GPUs—often across multiple servers—while managing communications overhead.
Practical distributed strategies might include data parallelism (splitting your dataset across multiple GPUs) or model parallelism (dividing the model's layers or parameters).
Tools like DeepSpeed or PyTorch's native distributed APIs automate some of the setup, but designing a truly efficient system requires an understanding of cluster topologies, network bandwidth, and memory sharing.
Also, beyond raw training, you'll also need to consider fault tolerance and reproducibility, so a background in distributed systems concepts, even at a high level, is increasingly valuable.
Overall, this means the data scientist of tomorrow is part statistician, part software engineer, and part systems architect.
New Learning Opportunities
In the past, only large companies or well-funded labs had the resources to maintain powerful on-premise GPU clusters. Today, cloud providers offer scalable GPU instances on demand, meaning students can rent the exact horsepower they need for a project, and only pay for what they use.
This lowers barriers to entry significantly. You can experiment with bigger models without needing upfront capital or dedicated hardware.
Universities and online platforms are increasingly offering classes on GPU programming, distributed machine learning, and HPC fundamentals.
These courses go beyond standard data science topics—covering everything from concurrency models to memory optimizations.
It's exciting that with the combination of accessible GPU resources and better educational materials, students can now tackle research problems once reserved for big tech or advance R&D groups. It's feasible for a student research team to achieve groundbreaking results on a relatively modest budget.
Career Path Implications
Of course, we may see new roles spring up.
The ML Infrastructure Engineer will focus on building and maintaining the backend systems that support large-scale AI. This may include configuring GPU clusters, managing distributed training frameworks, and facilitating model deployment.
The AI Systems Designer would specialize in selecting and orchestrating hardware, interconnects (NVLink or InfiniBand), and parallelization strategies.
The Compiler Optimization Engineer would work on tuning compilers and libraries so that neural network operations map efficiently to GPUs.
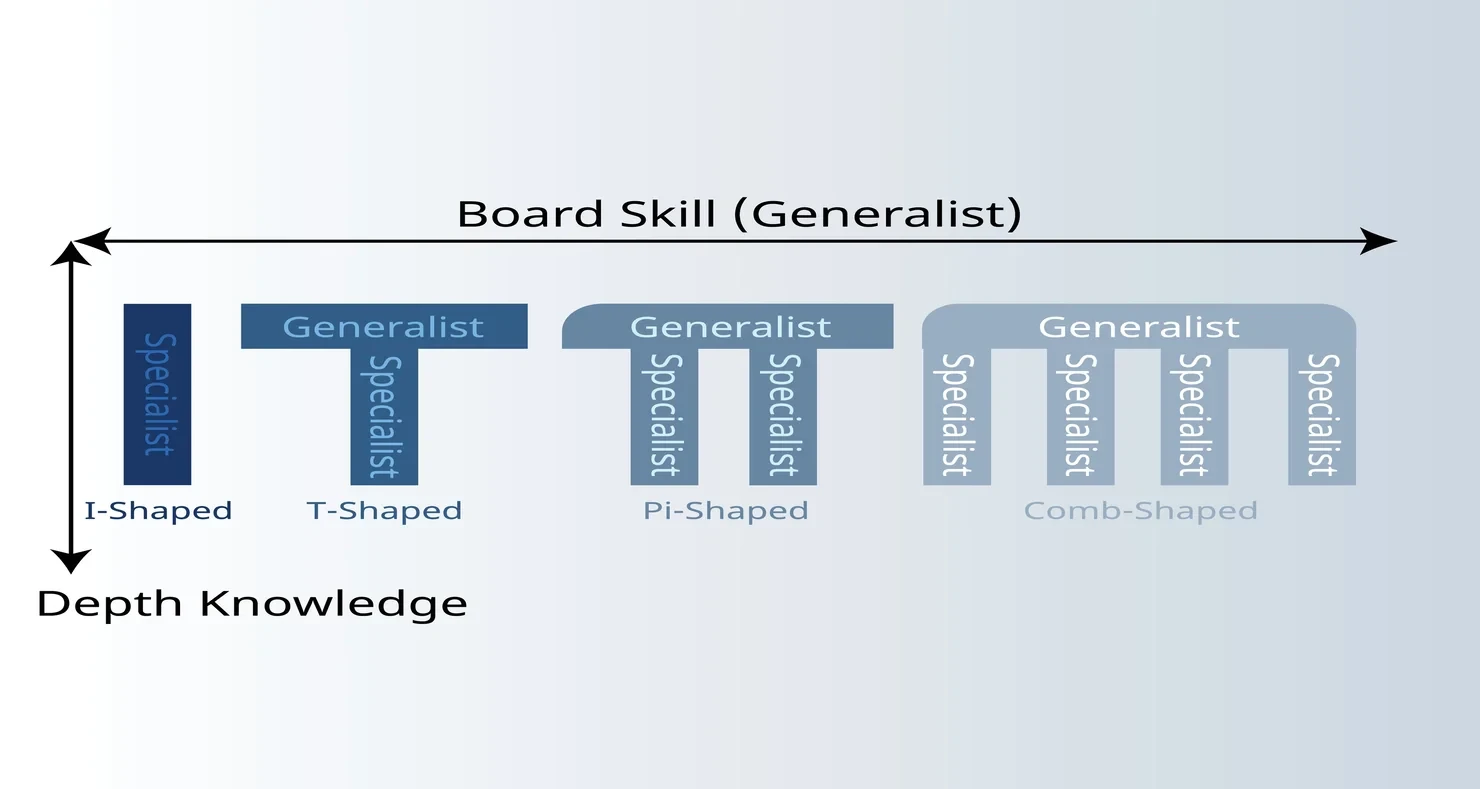
For many of these roles, you will find these people with a 'T-shaped' profile—for example, broad exposure to systems and infrastructure, plus deep expertise in a specific ML domain—positions you to both innovate and troubleshoot at any level of the stack.
As AI models continue to evolve, the underlying hardware will keep changing, too.
Individuals who know how to adapt to new GPU architectures or specialized hardware—whether that's through mixed-precision computing, on-the-fly compiler optimizations, or advanced distribution techniques—remain highly employable and can pivot quickly as new technologies emerge.
Understanding T-Shaped Skills
When we talk about T-shaped skills, we're referring to a combination of broad knowledge plus one area of deep expertise.
The horizontal bar of the 'T' represents your essential breadth—areas like technical literacy, systems thinking, business context, ethical considerations, and communication.
The vertical bar of the 'T' represents the area you choose to specialize in.
This could be an infrastructure specialty—maybe you're the go-to person for scaling machine learning on large GPU clusters. Or you might aim to become a domain expert in healthcare, finance, climate science, applying AI solutions in those fields.
Alternatively, you could focus on algorithmic innovation, like how models are structured or trained.
Ultimately, the key question is: Where do you want to develop your deep expertise?
Identifying that vertical focus is what will give you a strong competitive edge, while your horizontal, cross-functional skills make you valuable in any collaborative environment.
It's this blend of depth and breadth that helps you stay adaptable in the rapidly changing AI world.
My Experience
I gained a great deal of breadth in areas of AI from various courses offered by HDSI, and my internships, which spanned industries from finance, real estate, hardware, to automotive. Some of my "horizontal skills" include LLMs and agents, time series forecasting, Python, efficient SQL, application design patterns, open source software, graph neural networks, and ML/DL frameworks.
The "vertical skill" I am working to develop is deep learning compilers. This means closing the gap between theoretical and achieved FLOPs, optimizing memory access patterns, implementing and understanding fusion operations in the computation graph that represents a neural network, and balancing between computation and communication.
Bear in mind that your vertical doesn't have to remain fixed. There are also a wealth of both specialists and generalists (see below) at NVIDIA, from my experiences. I've talked to Solutions Architect that, in their work, must "know enough about a lot".
GPU Technology and the Data Science Students
As the AI landscape evolves at a breakneck pace, there's a rapidly growing need for data scientists who understand how to leverage parallel computing, distributed training, and specialized libraries.
In other words, it's no longer just about knowing machine learning algorithms; it's also about understanding the platforms that make these algorithms run efficiently at scale.
I am going to go into how being fluent in GPU-accelerated data science gives you a competitive edge as AI continues to expand into every corner of industry and academia.
Changing Skill Requirements
Today's data scientists increasingly need to know how their frameworks tap into GPU resources.
This doesn't need to be about writing low-level GPU kernels from scratch, but it does involve understanding how tensor operations map on to GPU threads or blocks.
This might include recognizing when your data loading it bottlenecking your GPU, or how asynchronous CPU/GPU operations can overlap to reduce idle time.
It's nice to have a mental of model of the GPU's concurrency and memory hierarchy, potential to boost training efficiency.
Even though GPUs are powerful, they're not always abundant. Cloud environments often charge by the minute or hour for GPU usage, and on-premise clusters are shared resources.
We're seeing techniques like model and gradient checkpointing, mixed precision, and layer-wise parallelism. These are no longer 'nice to have features"; they can be the difference between training a model in days versus weeks, or paying thousands of dollars versus tens of thousands.
Additionally, choosing the right GPU instance type or optimizing batch sizes can have huge cost implications. The more you understand memory footprints and parallel workloads, the more effective you'll be in budgeting and scaling your experiments.
Single-GPU training is becoming increasingly unrealistic as models balloon into billions or trillions of parameters. You'll need to design systems that coordinate multiple GPUs—often across multiple servers—while managing communications overhead.
Practical distributed strategies might include data parallelism (splitting your dataset across multiple GPUs) or model parallelism (dividing the model's layers or parameters).
Tools like DeepSpeed or PyTorch's native distributed APIs automate some of the setup, but designing a truly efficient system requires an understanding of cluster topologies, network bandwidth, and memory sharing.
Also, beyond raw training, you'll also need to consider fault tolerance and reproducibility, so a background in distributed systems concepts, even at a high level, is increasingly valuable.
Overall, this means the data scientist of tomorrow is part statistician, part software engineer, and part systems architect.
New Learning Opportunities
In the past, only large companies or well-funded labs had the resources to maintain powerful on-premise GPU clusters. Today, cloud providers offer scalable GPU instances on demand, meaning students can rent the exact horsepower they need for a project, and only pay for what they use.
This lowers barriers to entry significantly. You can experiment with bigger models without needing upfront capital or dedicated hardware.
Universities and online platforms are increasingly offering classes on GPU programming, distributed machine learning, and HPC fundamentals.
These courses go beyond standard data science topics—covering everything from concurrency models to memory optimizations.
It's exciting that with the combination of accessible GPU resources and better educational materials, students can now tackle research problems once reserved for big tech or advance R&D groups. It's feasible for a student research team to achieve groundbreaking results on a relatively modest budget.
Career Path Implications
Of course, we may see new roles spring up.
The ML Infrastructure Engineer will focus on building and maintaining the backend systems that support large-scale AI. This may include configuring GPU clusters, managing distributed training frameworks, and facilitating model deployment.
The AI Systems Designer would specialize in selecting and orchestrating hardware, interconnects (NVLink or InfiniBand), and parallelization strategies.
The Compiler Optimization Engineer would work on tuning compilers and libraries so that neural network operations map efficiently to GPUs.
For many of these roles, you will find these people with a 'T-shaped' profile—for example, broad exposure to systems and infrastructure, plus deep expertise in a specific ML domain—positions you to both innovate and troubleshoot at any level of the stack.
As AI models continue to evolve, the underlying hardware will keep changing, too.
Individuals who know how to adapt to new GPU architectures or specialized hardware—whether that's through mixed-precision computing, on-the-fly compiler optimizations, or advanced distribution techniques—remain highly employable and can pivot quickly as new technologies emerge.
Understanding T-Shaped Skills
When we talk about T-shaped skills, we're referring to a combination of broad knowledge plus one area of deep expertise.
The horizontal bar of the 'T' represents your essential breadth—areas like technical literacy, systems thinking, business context, ethical considerations, and communication.
The vertical bar of the 'T' represents the area you choose to specialize in.
This could be an infrastructure specialty—maybe you're the go-to person for scaling machine learning on large GPU clusters. Or you might aim to become a domain expert in healthcare, finance, climate science, applying AI solutions in those fields.
Alternatively, you could focus on algorithmic innovation, like how models are structured or trained.
Ultimately, the key question is: Where do you want to develop your deep expertise?
Identifying that vertical focus is what will give you a strong competitive edge, while your horizontal, cross-functional skills make you valuable in any collaborative environment.
It's this blend of depth and breadth that helps you stay adaptable in the rapidly changing AI world.
My Experience
I gained a great deal of breadth in areas of AI from various courses offered by HDSI, and my internships, which spanned industries from finance, real estate, hardware, to automotive. Some of my "horizontal skills" include LLMs and agents, time series forecasting, Python, efficient SQL, application design patterns, open source software, graph neural networks, and ML/DL frameworks.
The "vertical skill" I am working to develop is deep learning compilers. This means closing the gap between theoretical and achieved FLOPs, optimizing memory access patterns, implementing and understanding fusion operations in the computation graph that represents a neural network, and balancing between computation and communication.
Bear in mind that your vertical doesn't have to remain fixed. There are also a wealth of both specialists and generalists (see below) at NVIDIA, from my experiences. I've talked to Solutions Architect that, in their work, must "know enough about a lot".
GPU Technology and the Data Science Students
As the AI landscape evolves at a breakneck pace, there's a rapidly growing need for data scientists who understand how to leverage parallel computing, distributed training, and specialized libraries.
In other words, it's no longer just about knowing machine learning algorithms; it's also about understanding the platforms that make these algorithms run efficiently at scale.
I am going to go into how being fluent in GPU-accelerated data science gives you a competitive edge as AI continues to expand into every corner of industry and academia.
Changing Skill Requirements
Today's data scientists increasingly need to know how their frameworks tap into GPU resources.
This doesn't need to be about writing low-level GPU kernels from scratch, but it does involve understanding how tensor operations map on to GPU threads or blocks.
This might include recognizing when your data loading it bottlenecking your GPU, or how asynchronous CPU/GPU operations can overlap to reduce idle time.
It's nice to have a mental of model of the GPU's concurrency and memory hierarchy, potential to boost training efficiency.
Even though GPUs are powerful, they're not always abundant. Cloud environments often charge by the minute or hour for GPU usage, and on-premise clusters are shared resources.
We're seeing techniques like model and gradient checkpointing, mixed precision, and layer-wise parallelism. These are no longer 'nice to have features"; they can be the difference between training a model in days versus weeks, or paying thousands of dollars versus tens of thousands.
Additionally, choosing the right GPU instance type or optimizing batch sizes can have huge cost implications. The more you understand memory footprints and parallel workloads, the more effective you'll be in budgeting and scaling your experiments.
Single-GPU training is becoming increasingly unrealistic as models balloon into billions or trillions of parameters. You'll need to design systems that coordinate multiple GPUs—often across multiple servers—while managing communications overhead.
Practical distributed strategies might include data parallelism (splitting your dataset across multiple GPUs) or model parallelism (dividing the model's layers or parameters).
Tools like DeepSpeed or PyTorch's native distributed APIs automate some of the setup, but designing a truly efficient system requires an understanding of cluster topologies, network bandwidth, and memory sharing.
Also, beyond raw training, you'll also need to consider fault tolerance and reproducibility, so a background in distributed systems concepts, even at a high level, is increasingly valuable.
Overall, this means the data scientist of tomorrow is part statistician, part software engineer, and part systems architect.
New Learning Opportunities
In the past, only large companies or well-funded labs had the resources to maintain powerful on-premise GPU clusters. Today, cloud providers offer scalable GPU instances on demand, meaning students can rent the exact horsepower they need for a project, and only pay for what they use.
This lowers barriers to entry significantly. You can experiment with bigger models without needing upfront capital or dedicated hardware.
Universities and online platforms are increasingly offering classes on GPU programming, distributed machine learning, and HPC fundamentals.
These courses go beyond standard data science topics—covering everything from concurrency models to memory optimizations.
It's exciting that with the combination of accessible GPU resources and better educational materials, students can now tackle research problems once reserved for big tech or advance R&D groups. It's feasible for a student research team to achieve groundbreaking results on a relatively modest budget.
Career Path Implications
Of course, we may see new roles spring up.
The ML Infrastructure Engineer will focus on building and maintaining the backend systems that support large-scale AI. This may include configuring GPU clusters, managing distributed training frameworks, and facilitating model deployment.
The AI Systems Designer would specialize in selecting and orchestrating hardware, interconnects (NVLink or InfiniBand), and parallelization strategies.
The Compiler Optimization Engineer would work on tuning compilers and libraries so that neural network operations map efficiently to GPUs.
For many of these roles, you will find these people with a 'T-shaped' profile—for example, broad exposure to systems and infrastructure, plus deep expertise in a specific ML domain—positions you to both innovate and troubleshoot at any level of the stack.
As AI models continue to evolve, the underlying hardware will keep changing, too.
Individuals who know how to adapt to new GPU architectures or specialized hardware—whether that's through mixed-precision computing, on-the-fly compiler optimizations, or advanced distribution techniques—remain highly employable and can pivot quickly as new technologies emerge.
Understanding T-Shaped Skills
When we talk about T-shaped skills, we're referring to a combination of broad knowledge plus one area of deep expertise.
The horizontal bar of the 'T' represents your essential breadth—areas like technical literacy, systems thinking, business context, ethical considerations, and communication.
The vertical bar of the 'T' represents the area you choose to specialize in.
This could be an infrastructure specialty—maybe you're the go-to person for scaling machine learning on large GPU clusters. Or you might aim to become a domain expert in healthcare, finance, climate science, applying AI solutions in those fields.
Alternatively, you could focus on algorithmic innovation, like how models are structured or trained.
Ultimately, the key question is: Where do you want to develop your deep expertise?
Identifying that vertical focus is what will give you a strong competitive edge, while your horizontal, cross-functional skills make you valuable in any collaborative environment.
It's this blend of depth and breadth that helps you stay adaptable in the rapidly changing AI world.
My Experience
I gained a great deal of breadth in areas of AI from various courses offered by HDSI, and my internships, which spanned industries from finance, real estate, hardware, to automotive. Some of my "horizontal skills" include LLMs and agents, time series forecasting, Python, efficient SQL, application design patterns, open source software, graph neural networks, and ML/DL frameworks.
The "vertical skill" I am working to develop is deep learning compilers. This means closing the gap between theoretical and achieved FLOPs, optimizing memory access patterns, implementing and understanding fusion operations in the computation graph that represents a neural network, and balancing between computation and communication.
Bear in mind that your vertical doesn't have to remain fixed. There are also a wealth of both specialists and generalists (see below) at NVIDIA, from my experiences. I've talked to Solutions Architect that, in their work, must "know enough about a lot".
At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
At the Frontlines of AI: Complete Speech
AI's Impact on Education: Schools of Thought
Goal: To help you, the students, navigate uncertainty and future-proof your education.
As someone working at NVIDIA, I see firsthand at how AI is reshaping countless industries—and education is no exception.
AI has become so ubiquitous that students now use it for everything from brainstorming research ideas to generating code snippets.
But with that ubiquity comes a lot of uncertainty about what skills to focus on, how to harness AI's capabilities responsibly, and where it fits into building you a solid educational foundation.
To help you navigate this, I want to a share a few different schools of thought, backed by insights from experts and academics who've studied AI's impact on learning.
It's important to note that simply having access to advanced hardware and AI models doesn't automatically guarantee deeper learning.
There’s a human element—your curiosity, your ability to interpret and validate results—that AI can’t replace.
That’s why an understanding of ethical considerations, data biases, and the broader societal implications of AI is also crucial.
Transformational Optimists
The ‘Transformational Optimist’ stance is about harnessing AI as a force multiplier.
First, LLMs can be viewed as a democratizing force in education by making advanced computational capabilities accessible to more learners, regardless of location of budget.
Ethan and Lilach Mollick at the Wharton School encapsulate the concept of these technologies serving as capability amplifiers in "Assigning AI: Seven Approaches for Students" (2023).
They outline roles such as AI-tutor, AI-mentor, AI-teammate, Ai-student, and AI-tool.
For instance, the authors tested an 'AI-tutor' concept in advanced coursework, like finance and data analytics, where iterative feedback from an LLM helped students tackle problem sets.
Students who actively "talked back" to the AI, probed its reasoning, asked follow-up questions, challenging its assumptions, demonstrated deeper mastery of the material than those who simply consumed AI-generated answers.
They also proposed the idea of an "AI-coach" for developing higher-level skills, such as strategic thinking and metacognition. Unlike a simple chatbot, a well-implemented AI-coach can push them to justify or refine their ideas.
Perhaps the most sophisticated approach is the "AI-student" model, where learners actually teach the AI a concept.
Making the AI "learn" from you forces you to articulate your reasoning, test your explanations, and address knowledge gaps.
What's particularly noteworthy is their emphasis on domain-specific customization. In pilot programs, LLMs fine-tuned on specific course material provided more targeted and accurate feedback.
Of course, this opens another can of worms, like ensuring consistent AI quality control and mitigating biased introduced by specialized training data.
Ultimately, this school of thought redefines the 'learning contract' between professors and students.
Students have the potential to see AI as both a tool and a partner, requiring high-level skills in prompt engineering, ethical stewardship, and critical analysis, while educators gain more time for personalized mentorship.
Critical Skeptics
The "Critical Skeptics" perspective raises concerns about relying too heavily on LLMs in education. One major worry is that skill atrophy occurs when students become overly dependent on AI-generated answers.
There's also skepticism about the accuracy and bias of AI outputs, as well as the extent to which LLMs truly "understand" the material.
Daron Acemoglu, an MIT economist and co-author of this "Power and Progress: Our Thousand-Year Struggle Over Technology and Prosperity" (2023), questions the assumption AI will automatically boost productivity.
He places in AI in the context of historical technology disruptions, arguing that skill-biased technologies can exacerbate income and opportunity gaps unless carefully managed.
He points to the digital divide as danger, whereby wealthier institutions and students benefit from AI tools, while under-resourced populations fall further behind.
Rather than viewing AI integration as inevitable or uniformly positive (taking a technological determinist approach), critical skeptics emphasize that we must ask: Is the technology merely replacing human expertise, or complementing it?
Acemoglu believes that complementary technologies can genuinely enhance human work, but automation-centric approaches risk devaluing human roles and may lead to job displacement. Basically, we can't embrace automation for its own sake, we need "machine usefulness" where AI supplements human expertise rather than displacing it.
From this standpoint, the issue isn't just whether AI works; it's whether it serves broader social and educational goals, such as equitable skill development and meaningful employment.
Pragmatic Integrationists
The "Pragmatic Integrationists" see Large Language Models not as replacements for educators or learners, but as powerful tools that augment human intelligence. Erik Brynjolfsson, from Stanford’s Digital Economy Lab, emphasizes in his work—particularly in The Turing Trap (2022) and Generative AI at Work (2023)—that we should shift from the traditional benchmark of AI ‘matching’ human capabilities to designing systems where humans and AI collaborate.
Brynjolfsson points out that focusing solely on AI's ability to replicate or replace human tasks can be a trap, since it overlooks the potential for complementary and collaborative skills.
Translating this into an educational context, we can imagine students getting a head start in mastering challenging material when paired with an AI "co-pilot." But just as important is rethinking course design an assessments so that AI's strength—pattern recognition, rapid information retrieval—amplify our creativity rather than supplant it, means structuring learning tasks to require uniquely human skills, like judgment, ethics, and original thinking, rather than tasks AI can easily do on its own.
Adopting AI effectively requires redesigning workflows and benchmarks. Rather than testing whether AI can "fool" a human—à la the Turing Test—he suggests we evaluate how well AI and humans can work together to achieve new levels of performance or insight.
This could mean new forms of assessment that let students showcase how they collaborate with AI.
Ultimately, the Pragmatic Integrationist approach encourages us to move beyond the mindset of "AI doing what humans do."
Instead, we can leverage the advantages of LLMs, like scalability, instant feedback, and vast content knowledge, to create innovative educational experiences.
Rethinking Learning in the AI Era
The saying "struggle is where learning happens" is especially relevant in the AI age. Sometimes, AI tools can short-circuit that struggle by handing us answers too quickly.
When we let an LLM solve a problem without stepping through our own reasoning, we risk missing out on identifying and correcting our misconceptions.
That's the crux of the metacognitive paradox: "Is AI helping me discover and resolve my gaps, or is it just bypassing them?"
Historically, education has focused on memorizing facts or formulas. Of course, content retention is now much less critical since AI can retrieve and generate information almost instantaneously.
What grows more valuable is the ability to judge and interpret information. In other words, knowing how to question and contextualize data is more important than possessing that data in your memory.
If an AI suggests a scientific paper, can you gauge its credibility? If an AI writes code, can you debug and verify it? When you develop these skills, you'll see that learning is transformed from collecting knowledge to evaluating and synthesizing knowledge.
Finally, there's a risk that when AI makes certain easy, we can become complacent.
Today's AI efficiency might cause us to cling to old methods or resist new technologies that could actually be better in the long run. This is similar to how organizations sometimes stick with legacy tools because they're "good enough," even though more advanced alternatives could yield greater benefits.
The key is to stay proactive: keep refining your skills, exploring new approaches, and remembering that AI is still evolving; it's not a fixed endpoint.
When you continue to embrace AI in your studies, you need to balance convenience with deeper engagement, and there's this continuing mindset shift from mere retention to critical evaluation.
Advanced AI Relationships
Another uncertainty you might run into is attribution: "How much credit can I take if AI does most of the heavy lifting?" If a system proposes an entire solution, did you actually learn? We need frameworks that clarify how much of a solution comes from you versus the AI.
In some advanced settings, you may be required to annotate or explain which portions are AI-generated and how they verified those steps.
That way, you can still demonstrate mastery rather than outsourcing cognition to an algorithm.
When we treat AI like an "expert model," we're not just grabbing the end result; we're delving into how the AI got there. This could involve reverse-engineering the AI outputs, asking it for alternative approaches or detailed reasoning, then comparing those to our own.
For instance, if AI produces code or a proof, request multiple versions or expansions at each step, and piece together and understanding of the underlying principles.
You want to use an AI response as a springboard for deeper inquiry.
Finally, a key meta-skill is recognizing when the AI is reliable or not. Just as experts learn to gauge the trustworthiness of different sources, we need to assess when an AI might be hallucinating, overlooking edge cases, or injecting biases.
Developing AI intuition here might mean noticing warning signs: contradictory statements, leaps in logic, or an inability to cite credible references.
This meta-skill is going to make you more adaptable and resilient when AI inevitably fails, because you're going to know how to pivot, cross-check, and retain ownership of your own learning.
Your Humanity is a Superpower
As we wrap up, I want to emphasize that your uniquely human capacities—meaning-making, ethical judgment, and creative connection—are not eclipsed by AI. In fact, they become more valuable as technology takes over routine tasks. Your ability to interpret subtle context, imagine possibilities beyond the data, and exercise moral discernment can’t be automated.
When I talk about "your humanity as a superpower," I'm pointing to everything that makes you adaptable, empathetic, and capable of seeing the bigger picture. AI may supply information, but it’s your perspective that weaves it into a deeper narrative, your sense of right and wrong that applies it ethically, and your creativity that sparks something entirely new.
Thank you to everyone that attended the speech, and asked questions at the end!
AI's Impact on Education: Schools of Thought
Goal: To help you, the students, navigate uncertainty and future-proof your education.
As someone working at NVIDIA, I see firsthand at how AI is reshaping countless industries—and education is no exception.
AI has become so ubiquitous that students now use it for everything from brainstorming research ideas to generating code snippets.
But with that ubiquity comes a lot of uncertainty about what skills to focus on, how to harness AI's capabilities responsibly, and where it fits into building you a solid educational foundation.
To help you navigate this, I want to a share a few different schools of thought, backed by insights from experts and academics who've studied AI's impact on learning.
It's important to note that simply having access to advanced hardware and AI models doesn't automatically guarantee deeper learning.
There’s a human element—your curiosity, your ability to interpret and validate results—that AI can’t replace.
That’s why an understanding of ethical considerations, data biases, and the broader societal implications of AI is also crucial.
Transformational Optimists
The ‘Transformational Optimist’ stance is about harnessing AI as a force multiplier.
First, LLMs can be viewed as a democratizing force in education by making advanced computational capabilities accessible to more learners, regardless of location of budget.
Ethan and Lilach Mollick at the Wharton School encapsulate the concept of these technologies serving as capability amplifiers in "Assigning AI: Seven Approaches for Students" (2023).
They outline roles such as AI-tutor, AI-mentor, AI-teammate, Ai-student, and AI-tool.
For instance, the authors tested an 'AI-tutor' concept in advanced coursework, like finance and data analytics, where iterative feedback from an LLM helped students tackle problem sets.
Students who actively "talked back" to the AI, probed its reasoning, asked follow-up questions, challenging its assumptions, demonstrated deeper mastery of the material than those who simply consumed AI-generated answers.
They also proposed the idea of an "AI-coach" for developing higher-level skills, such as strategic thinking and metacognition. Unlike a simple chatbot, a well-implemented AI-coach can push them to justify or refine their ideas.
Perhaps the most sophisticated approach is the "AI-student" model, where learners actually teach the AI a concept.
Making the AI "learn" from you forces you to articulate your reasoning, test your explanations, and address knowledge gaps.
What's particularly noteworthy is their emphasis on domain-specific customization. In pilot programs, LLMs fine-tuned on specific course material provided more targeted and accurate feedback.
Of course, this opens another can of worms, like ensuring consistent AI quality control and mitigating biased introduced by specialized training data.
Ultimately, this school of thought redefines the 'learning contract' between professors and students.
Students have the potential to see AI as both a tool and a partner, requiring high-level skills in prompt engineering, ethical stewardship, and critical analysis, while educators gain more time for personalized mentorship.
Critical Skeptics
The "Critical Skeptics" perspective raises concerns about relying too heavily on LLMs in education. One major worry is that skill atrophy occurs when students become overly dependent on AI-generated answers.
There's also skepticism about the accuracy and bias of AI outputs, as well as the extent to which LLMs truly "understand" the material.
Daron Acemoglu, an MIT economist and co-author of this "Power and Progress: Our Thousand-Year Struggle Over Technology and Prosperity" (2023), questions the assumption AI will automatically boost productivity.
He places in AI in the context of historical technology disruptions, arguing that skill-biased technologies can exacerbate income and opportunity gaps unless carefully managed.
He points to the digital divide as danger, whereby wealthier institutions and students benefit from AI tools, while under-resourced populations fall further behind.
Rather than viewing AI integration as inevitable or uniformly positive (taking a technological determinist approach), critical skeptics emphasize that we must ask: Is the technology merely replacing human expertise, or complementing it?
Acemoglu believes that complementary technologies can genuinely enhance human work, but automation-centric approaches risk devaluing human roles and may lead to job displacement. Basically, we can't embrace automation for its own sake, we need "machine usefulness" where AI supplements human expertise rather than displacing it.
From this standpoint, the issue isn't just whether AI works; it's whether it serves broader social and educational goals, such as equitable skill development and meaningful employment.
Pragmatic Integrationists
The "Pragmatic Integrationists" see Large Language Models not as replacements for educators or learners, but as powerful tools that augment human intelligence. Erik Brynjolfsson, from Stanford’s Digital Economy Lab, emphasizes in his work—particularly in The Turing Trap (2022) and Generative AI at Work (2023)—that we should shift from the traditional benchmark of AI ‘matching’ human capabilities to designing systems where humans and AI collaborate.
Brynjolfsson points out that focusing solely on AI's ability to replicate or replace human tasks can be a trap, since it overlooks the potential for complementary and collaborative skills.
Translating this into an educational context, we can imagine students getting a head start in mastering challenging material when paired with an AI "co-pilot." But just as important is rethinking course design an assessments so that AI's strength—pattern recognition, rapid information retrieval—amplify our creativity rather than supplant it, means structuring learning tasks to require uniquely human skills, like judgment, ethics, and original thinking, rather than tasks AI can easily do on its own.
Adopting AI effectively requires redesigning workflows and benchmarks. Rather than testing whether AI can "fool" a human—à la the Turing Test—he suggests we evaluate how well AI and humans can work together to achieve new levels of performance or insight.
This could mean new forms of assessment that let students showcase how they collaborate with AI.
Ultimately, the Pragmatic Integrationist approach encourages us to move beyond the mindset of "AI doing what humans do."
Instead, we can leverage the advantages of LLMs, like scalability, instant feedback, and vast content knowledge, to create innovative educational experiences.
Rethinking Learning in the AI Era
The saying "struggle is where learning happens" is especially relevant in the AI age. Sometimes, AI tools can short-circuit that struggle by handing us answers too quickly.
When we let an LLM solve a problem without stepping through our own reasoning, we risk missing out on identifying and correcting our misconceptions.
That's the crux of the metacognitive paradox: "Is AI helping me discover and resolve my gaps, or is it just bypassing them?"
Historically, education has focused on memorizing facts or formulas. Of course, content retention is now much less critical since AI can retrieve and generate information almost instantaneously.
What grows more valuable is the ability to judge and interpret information. In other words, knowing how to question and contextualize data is more important than possessing that data in your memory.
If an AI suggests a scientific paper, can you gauge its credibility? If an AI writes code, can you debug and verify it? When you develop these skills, you'll see that learning is transformed from collecting knowledge to evaluating and synthesizing knowledge.
Finally, there's a risk that when AI makes certain easy, we can become complacent.
Today's AI efficiency might cause us to cling to old methods or resist new technologies that could actually be better in the long run. This is similar to how organizations sometimes stick with legacy tools because they're "good enough," even though more advanced alternatives could yield greater benefits.
The key is to stay proactive: keep refining your skills, exploring new approaches, and remembering that AI is still evolving; it's not a fixed endpoint.
When you continue to embrace AI in your studies, you need to balance convenience with deeper engagement, and there's this continuing mindset shift from mere retention to critical evaluation.
Advanced AI Relationships
Another uncertainty you might run into is attribution: "How much credit can I take if AI does most of the heavy lifting?" If a system proposes an entire solution, did you actually learn? We need frameworks that clarify how much of a solution comes from you versus the AI.
In some advanced settings, you may be required to annotate or explain which portions are AI-generated and how they verified those steps.
That way, you can still demonstrate mastery rather than outsourcing cognition to an algorithm.
When we treat AI like an "expert model," we're not just grabbing the end result; we're delving into how the AI got there. This could involve reverse-engineering the AI outputs, asking it for alternative approaches or detailed reasoning, then comparing those to our own.
For instance, if AI produces code or a proof, request multiple versions or expansions at each step, and piece together and understanding of the underlying principles.
You want to use an AI response as a springboard for deeper inquiry.
Finally, a key meta-skill is recognizing when the AI is reliable or not. Just as experts learn to gauge the trustworthiness of different sources, we need to assess when an AI might be hallucinating, overlooking edge cases, or injecting biases.
Developing AI intuition here might mean noticing warning signs: contradictory statements, leaps in logic, or an inability to cite credible references.
This meta-skill is going to make you more adaptable and resilient when AI inevitably fails, because you're going to know how to pivot, cross-check, and retain ownership of your own learning.
Your Humanity is a Superpower
As we wrap up, I want to emphasize that your uniquely human capacities—meaning-making, ethical judgment, and creative connection—are not eclipsed by AI. In fact, they become more valuable as technology takes over routine tasks. Your ability to interpret subtle context, imagine possibilities beyond the data, and exercise moral discernment can’t be automated.
When I talk about "your humanity as a superpower," I'm pointing to everything that makes you adaptable, empathetic, and capable of seeing the bigger picture. AI may supply information, but it’s your perspective that weaves it into a deeper narrative, your sense of right and wrong that applies it ethically, and your creativity that sparks something entirely new.
Thank you to everyone that attended the speech, and asked questions at the end!
AI's Impact on Education: Schools of Thought
Goal: To help you, the students, navigate uncertainty and future-proof your education.
As someone working at NVIDIA, I see firsthand at how AI is reshaping countless industries—and education is no exception.
AI has become so ubiquitous that students now use it for everything from brainstorming research ideas to generating code snippets.
But with that ubiquity comes a lot of uncertainty about what skills to focus on, how to harness AI's capabilities responsibly, and where it fits into building you a solid educational foundation.
To help you navigate this, I want to a share a few different schools of thought, backed by insights from experts and academics who've studied AI's impact on learning.
It's important to note that simply having access to advanced hardware and AI models doesn't automatically guarantee deeper learning.
There’s a human element—your curiosity, your ability to interpret and validate results—that AI can’t replace.
That’s why an understanding of ethical considerations, data biases, and the broader societal implications of AI is also crucial.
Transformational Optimists
The ‘Transformational Optimist’ stance is about harnessing AI as a force multiplier.
First, LLMs can be viewed as a democratizing force in education by making advanced computational capabilities accessible to more learners, regardless of location of budget.
Ethan and Lilach Mollick at the Wharton School encapsulate the concept of these technologies serving as capability amplifiers in "Assigning AI: Seven Approaches for Students" (2023).
They outline roles such as AI-tutor, AI-mentor, AI-teammate, Ai-student, and AI-tool.
For instance, the authors tested an 'AI-tutor' concept in advanced coursework, like finance and data analytics, where iterative feedback from an LLM helped students tackle problem sets.
Students who actively "talked back" to the AI, probed its reasoning, asked follow-up questions, challenging its assumptions, demonstrated deeper mastery of the material than those who simply consumed AI-generated answers.
They also proposed the idea of an "AI-coach" for developing higher-level skills, such as strategic thinking and metacognition. Unlike a simple chatbot, a well-implemented AI-coach can push them to justify or refine their ideas.
Perhaps the most sophisticated approach is the "AI-student" model, where learners actually teach the AI a concept.
Making the AI "learn" from you forces you to articulate your reasoning, test your explanations, and address knowledge gaps.
What's particularly noteworthy is their emphasis on domain-specific customization. In pilot programs, LLMs fine-tuned on specific course material provided more targeted and accurate feedback.
Of course, this opens another can of worms, like ensuring consistent AI quality control and mitigating biased introduced by specialized training data.
Ultimately, this school of thought redefines the 'learning contract' between professors and students.
Students have the potential to see AI as both a tool and a partner, requiring high-level skills in prompt engineering, ethical stewardship, and critical analysis, while educators gain more time for personalized mentorship.
Critical Skeptics
The "Critical Skeptics" perspective raises concerns about relying too heavily on LLMs in education. One major worry is that skill atrophy occurs when students become overly dependent on AI-generated answers.
There's also skepticism about the accuracy and bias of AI outputs, as well as the extent to which LLMs truly "understand" the material.
Daron Acemoglu, an MIT economist and co-author of this "Power and Progress: Our Thousand-Year Struggle Over Technology and Prosperity" (2023), questions the assumption AI will automatically boost productivity.
He places in AI in the context of historical technology disruptions, arguing that skill-biased technologies can exacerbate income and opportunity gaps unless carefully managed.
He points to the digital divide as danger, whereby wealthier institutions and students benefit from AI tools, while under-resourced populations fall further behind.
Rather than viewing AI integration as inevitable or uniformly positive (taking a technological determinist approach), critical skeptics emphasize that we must ask: Is the technology merely replacing human expertise, or complementing it?
Acemoglu believes that complementary technologies can genuinely enhance human work, but automation-centric approaches risk devaluing human roles and may lead to job displacement. Basically, we can't embrace automation for its own sake, we need "machine usefulness" where AI supplements human expertise rather than displacing it.
From this standpoint, the issue isn't just whether AI works; it's whether it serves broader social and educational goals, such as equitable skill development and meaningful employment.
Pragmatic Integrationists
The "Pragmatic Integrationists" see Large Language Models not as replacements for educators or learners, but as powerful tools that augment human intelligence. Erik Brynjolfsson, from Stanford’s Digital Economy Lab, emphasizes in his work—particularly in The Turing Trap (2022) and Generative AI at Work (2023)—that we should shift from the traditional benchmark of AI ‘matching’ human capabilities to designing systems where humans and AI collaborate.
Brynjolfsson points out that focusing solely on AI's ability to replicate or replace human tasks can be a trap, since it overlooks the potential for complementary and collaborative skills.
Translating this into an educational context, we can imagine students getting a head start in mastering challenging material when paired with an AI "co-pilot." But just as important is rethinking course design an assessments so that AI's strength—pattern recognition, rapid information retrieval—amplify our creativity rather than supplant it, means structuring learning tasks to require uniquely human skills, like judgment, ethics, and original thinking, rather than tasks AI can easily do on its own.
Adopting AI effectively requires redesigning workflows and benchmarks. Rather than testing whether AI can "fool" a human—à la the Turing Test—he suggests we evaluate how well AI and humans can work together to achieve new levels of performance or insight.
This could mean new forms of assessment that let students showcase how they collaborate with AI.
Ultimately, the Pragmatic Integrationist approach encourages us to move beyond the mindset of "AI doing what humans do."
Instead, we can leverage the advantages of LLMs, like scalability, instant feedback, and vast content knowledge, to create innovative educational experiences.
Rethinking Learning in the AI Era
The saying "struggle is where learning happens" is especially relevant in the AI age. Sometimes, AI tools can short-circuit that struggle by handing us answers too quickly.
When we let an LLM solve a problem without stepping through our own reasoning, we risk missing out on identifying and correcting our misconceptions.
That's the crux of the metacognitive paradox: "Is AI helping me discover and resolve my gaps, or is it just bypassing them?"
Historically, education has focused on memorizing facts or formulas. Of course, content retention is now much less critical since AI can retrieve and generate information almost instantaneously.
What grows more valuable is the ability to judge and interpret information. In other words, knowing how to question and contextualize data is more important than possessing that data in your memory.
If an AI suggests a scientific paper, can you gauge its credibility? If an AI writes code, can you debug and verify it? When you develop these skills, you'll see that learning is transformed from collecting knowledge to evaluating and synthesizing knowledge.
Finally, there's a risk that when AI makes certain easy, we can become complacent.
Today's AI efficiency might cause us to cling to old methods or resist new technologies that could actually be better in the long run. This is similar to how organizations sometimes stick with legacy tools because they're "good enough," even though more advanced alternatives could yield greater benefits.
The key is to stay proactive: keep refining your skills, exploring new approaches, and remembering that AI is still evolving; it's not a fixed endpoint.
When you continue to embrace AI in your studies, you need to balance convenience with deeper engagement, and there's this continuing mindset shift from mere retention to critical evaluation.
Advanced AI Relationships
Another uncertainty you might run into is attribution: "How much credit can I take if AI does most of the heavy lifting?" If a system proposes an entire solution, did you actually learn? We need frameworks that clarify how much of a solution comes from you versus the AI.
In some advanced settings, you may be required to annotate or explain which portions are AI-generated and how they verified those steps.
That way, you can still demonstrate mastery rather than outsourcing cognition to an algorithm.
When we treat AI like an "expert model," we're not just grabbing the end result; we're delving into how the AI got there. This could involve reverse-engineering the AI outputs, asking it for alternative approaches or detailed reasoning, then comparing those to our own.
For instance, if AI produces code or a proof, request multiple versions or expansions at each step, and piece together and understanding of the underlying principles.
You want to use an AI response as a springboard for deeper inquiry.
Finally, a key meta-skill is recognizing when the AI is reliable or not. Just as experts learn to gauge the trustworthiness of different sources, we need to assess when an AI might be hallucinating, overlooking edge cases, or injecting biases.
Developing AI intuition here might mean noticing warning signs: contradictory statements, leaps in logic, or an inability to cite credible references.
This meta-skill is going to make you more adaptable and resilient when AI inevitably fails, because you're going to know how to pivot, cross-check, and retain ownership of your own learning.
Your Humanity is a Superpower
As we wrap up, I want to emphasize that your uniquely human capacities—meaning-making, ethical judgment, and creative connection—are not eclipsed by AI. In fact, they become more valuable as technology takes over routine tasks. Your ability to interpret subtle context, imagine possibilities beyond the data, and exercise moral discernment can’t be automated.
When I talk about "your humanity as a superpower," I'm pointing to everything that makes you adaptable, empathetic, and capable of seeing the bigger picture. AI may supply information, but it’s your perspective that weaves it into a deeper narrative, your sense of right and wrong that applies it ethically, and your creativity that sparks something entirely new.
Thank you to everyone that attended the speech, and asked questions at the end!
More Blogs More Blogs
Let's Chat
BASED IN the Bay Area,
CALIFORNIA

AI Engineer
+ Musician and Artist
Let's Chat
BASED IN the Bay Area,
CALIFORNIA
AI Engineer
+ Musician and Artist
Let's Chat
Let's Chat
BASED IN the Bay Area,
CALIFORNIA
AI Engineer
+ Musician and Artist